JAVA代码编译流程是怎样的?
前言
写了这么多年的代码,对于java代码运行的全流程你心里有清晰的脉络吗?
大家会不会跟我最开始一样,觉得在IDE里点一下RUN按钮,我们写的代码就直接直接跑起来了吧?

俗话说的好,你觉得生活静好,其实只是因为有人在为你负重前行,编译器和虚拟机默默的承受了这一切。
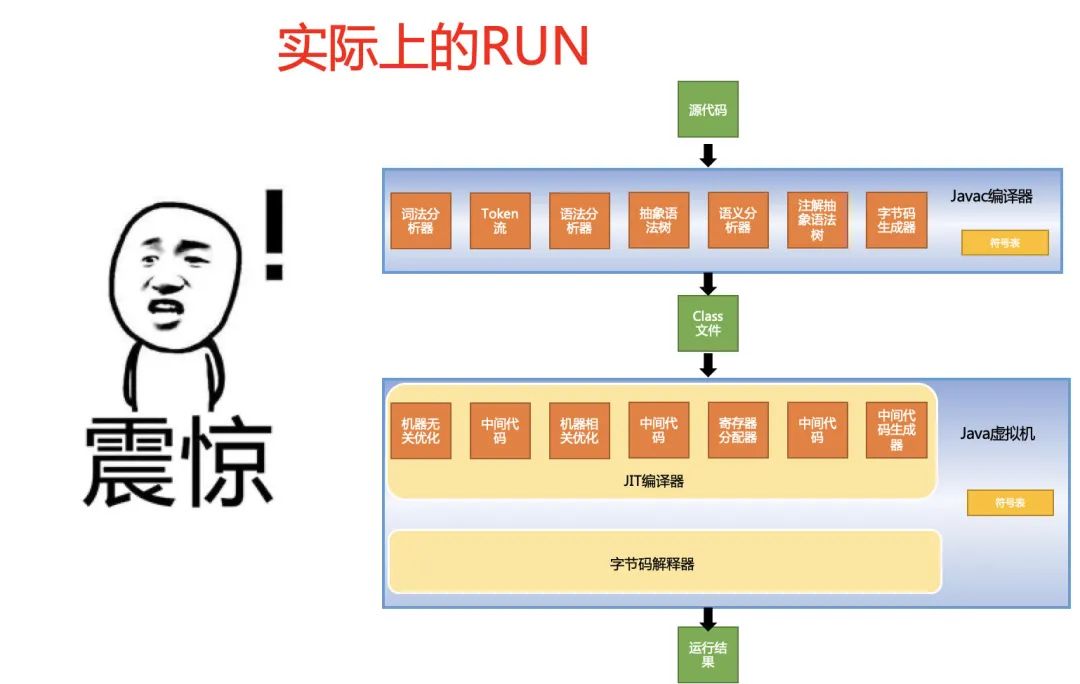
小小的一个RUN,背后却是很多组件共同努力的结果,它们必须非常努力,才能看起来毫不费力。
今天就让我们花点篇幅,来好好聊聊,Java代码RUN起来的背后,那些默默付出的大功臣们。
当我们写下一行代码时,我们到底在写什么?
夜深了,我们在屏幕上打下一段优雅的代码,一边拧开泡着枸杞的保温杯抿了一口热水,一边欣赏自己诗一样的代码,心里默默地夸了一波自己:不愧是我!

第一个问题来了,计算机真的能看到我们写的”诗“吗?
众所周知,Java是一门"一次编写,到处运行"的语言,也就是所谓的平台无关性,不管在哪个平台都能够运行,且保证运行的结果与期待的一致。(这是大学老师反复强调的)
Java实现”平台无关性“的原理也非常简单,就是利用中间格式来进行过渡,也就是我们常说的字节码,通过将Java源代码转换成字节码,保证JVM(Java虚拟机)读取到的一定是自己能够识别的字节码格式。

一个通俗的解释:你不会说法语,法国人不会讲中文,但是你们或多或少都会点英语,把英语作为你们的中间格式,保证双方都能明白对方的意思,这就是所谓的跨平台。
Java源码首先被编译成字节码,而这个字节码就是实现平台无关性的关键,无论你是什么类型的平台,只要你安装了能够识别字节码的JVM(Java虚拟机),通过JVM对字节码文件进行解析,把字节码转换成具体平台上的机器指令,就可以实现跨平台的运行了。
因此别说让计算机底层读到我们写的”代码诗“了,就连Java虚拟机都拿不到我们原汁原味的代码,在编译器的努力下,Java源代码已经变成大白话的class文件了。
所以啊宝,操作系统欣赏不到我们”诗一样的代码“,我们所写的每一行代码,都会变成一条条指令,对操作系统来说,它看到的不是编程的艺术,只是自己需要完成的一条条KPI罢了。

文本即代码?
如果我们写了具有同样内容的Java文件和txt文本,他们在文本编辑器中长得是没有区别的。
有一句名言是:世界上最好的IDE是txt文本编辑器。现在我们可能用IDE都用顺手了,很多的操作我们都习惯于让IDE给我们提示,依赖于IDE的代码补全和快捷键。
但在传说中,有一群用记事本就能打出优美代码的大佬,到了这个境界时,已经是人码合一,无需语法高亮,无需补全提示,所有的正确语法都了然于心,打出来的每一行代码都是可以直接编译run起来且零BUG的好代码(doge)。
扯得有点远了,但用记事本确实是可以实现开发功能,只要你自己打的代码逻辑正确,且没有语法错误,最后保存的后缀是.java,就能作为代码去运行了。
因此,从本质来说,我们所打出来的txt文本和Java代码在一开始是没有多大区别的,用普通的文本编辑器也能打开我们的.java后缀的文件。但是文本编辑器能做到的也仅仅限于看到.java文件里面的代码文本而已了。
Java编译器才是最终,能够识别并理解.java文件的存在。
Java代码想要运行起来,第一步就是得到编译器的认可。编译器的任务很简单,就是将符合Java语言源码编译为符合 Java虚拟机规范的Class文件,如果输入的Java源码不符合规范则需要报告错误。
可以说,编译的过程是Java开发的第一小步,但也是程序的一大步。
接下来我们先介绍一下编译器在Java体系中的位置。
JDK与JRE的爱恨情仇
在我们初学java时,一定安装过所谓的java环境,当我们自信满满地点进了Oracle的Java官网,映入眼帘的是两个看起来很像的安装包:
这我就蒙蔽了呀,我就想装个Java环境,怎么有两个奇奇怪怪的安装包,一个叫JDK,一个叫JRE,这两个安装包跟俗称的”Java“又有什么关系?
先理清楚所谓的JDK和JRE到底有什么区别吧,来看一张Java 8的体系架构图(https://docs.oracle.com/javase/8/docs/):
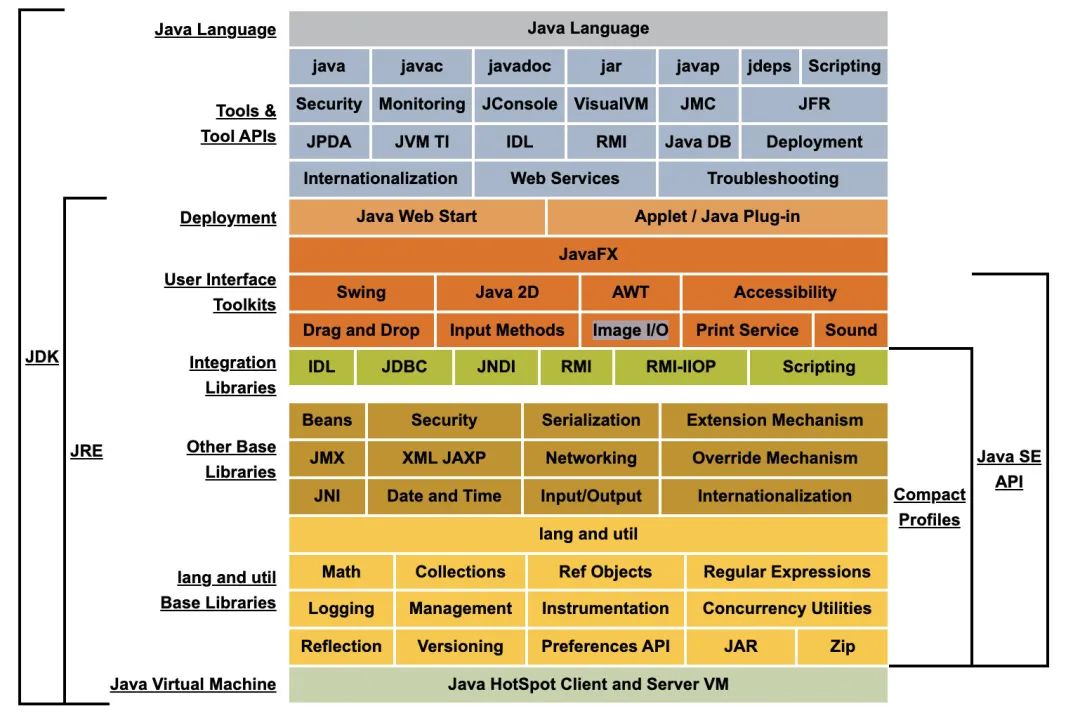
JDK全称是Java开发工具包(Java Development Kit),它包含了Java从开发到运行的各种工具。
JRE指的则是Java运行环境(Java Runtime Environment),它包含了基础类库和JVM虚拟机。
上图展示的是Java 8的体系结构,最左边的一栏很清晰的表明了JDK和JRE各自的范围,我们也很容易发现:
JRE是JDK的子集。
既然你要搞开发,肯定得保证自己写的代码能运行起来吧,所以当开发人员安装好JDK之后里面已经包含了一个运行环境JRE,保证自己的代码能够得到运行和验证,这就是为什么JRE被包含在JDK中。
但如果我们是普通用户,并不关心开发,甚至根本不懂代码,我只想要代码跑起来的结果,那只需要本地有JRE运行环境就行了。
如果用过零几年的按键手机,你就会深有体会,那时候很多的手机软件都是用Java编写的,只需要一个JAR包,你就能收获快乐。

反向思维一下,既然安装JRE就能运行JAVA代码,但要需要完整的JDK才能完成开发,那他们之间的差集肯定跟开发的过程有关。
所以接下来,我们来探讨一下为什么缺少这一块内容就只能成为运行环境,而不能承担开发功能呢?
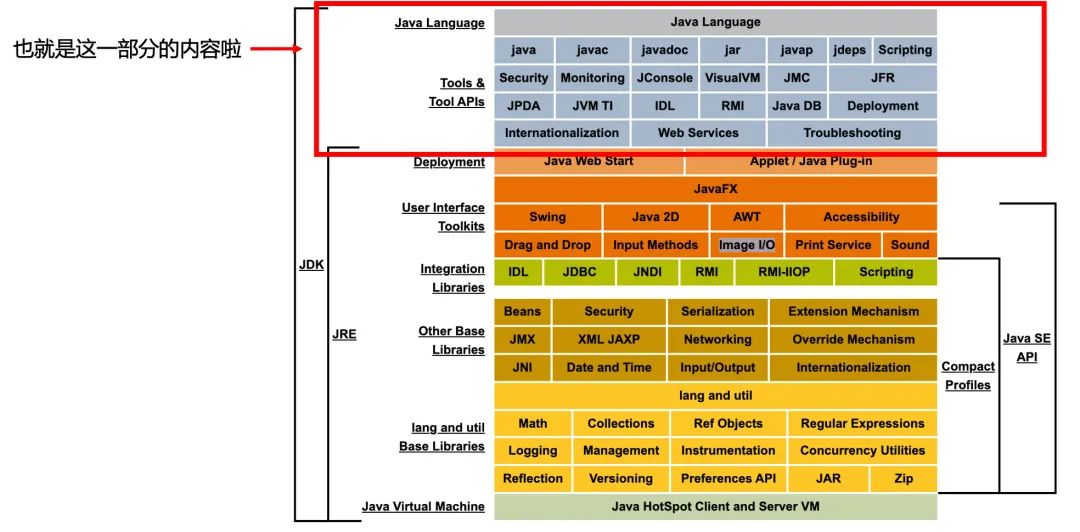
这一块里我们可以看到几个很熟悉的命令:
-
javac:用于编译java源代码,生成class文件; -
javap:用于反编译,根据class文件,反解析出其中的汇编指令和其他信息; -
javadoc:用于生成java文档的命令。
其中,我们最常用的、最重要的就是javac命令。这是JDK中内嵌的编译器,通过这个命令,可以将java源文件转换成class文件。这个javac编译器就是JRE相比于JDK少了开发功能的决定性元素!!
我们用一个简单的例子看看,开发者编写好的java代码在完整的JDK架构下,经过JDK、JRE以及JVM的运行过程。
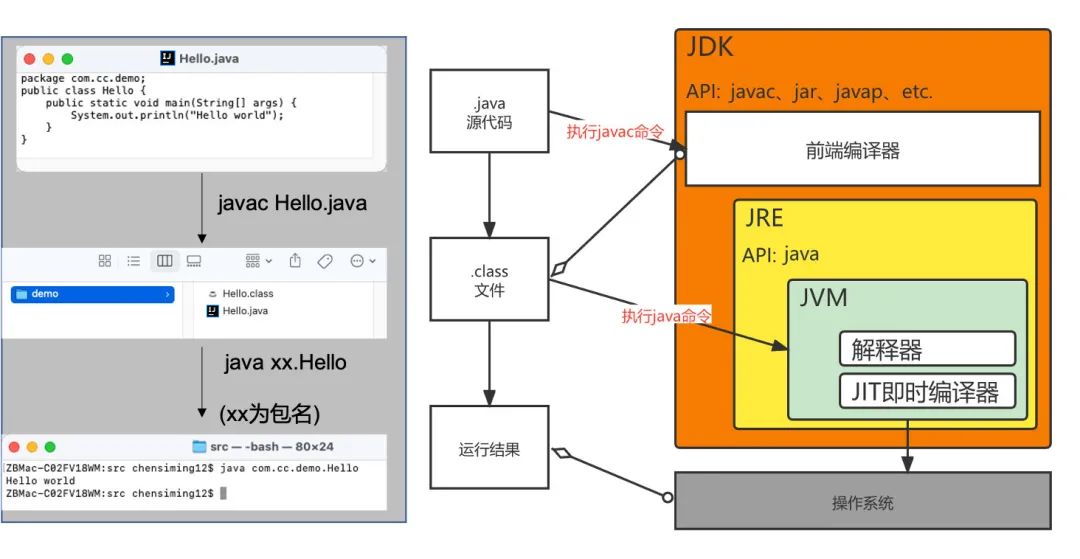
可以看到,通过JDK中的javac命令,我们才能将java源代码编译成class文件,而前面也提到了,这个class文件才是最终放到JVM中运行的文件。
我们把java源码到class文件的过程称之为编译阶段,把class文件到JVM中运行得到结果的阶段称为运行阶段。
因此,如果只有JRE而没有完整的JDK的话,相当于就少了编译源代码的关键工具,你只能依赖人家传递的,已经编译好的class代码,将程序运行起来,而不具备修改、开发的能力。
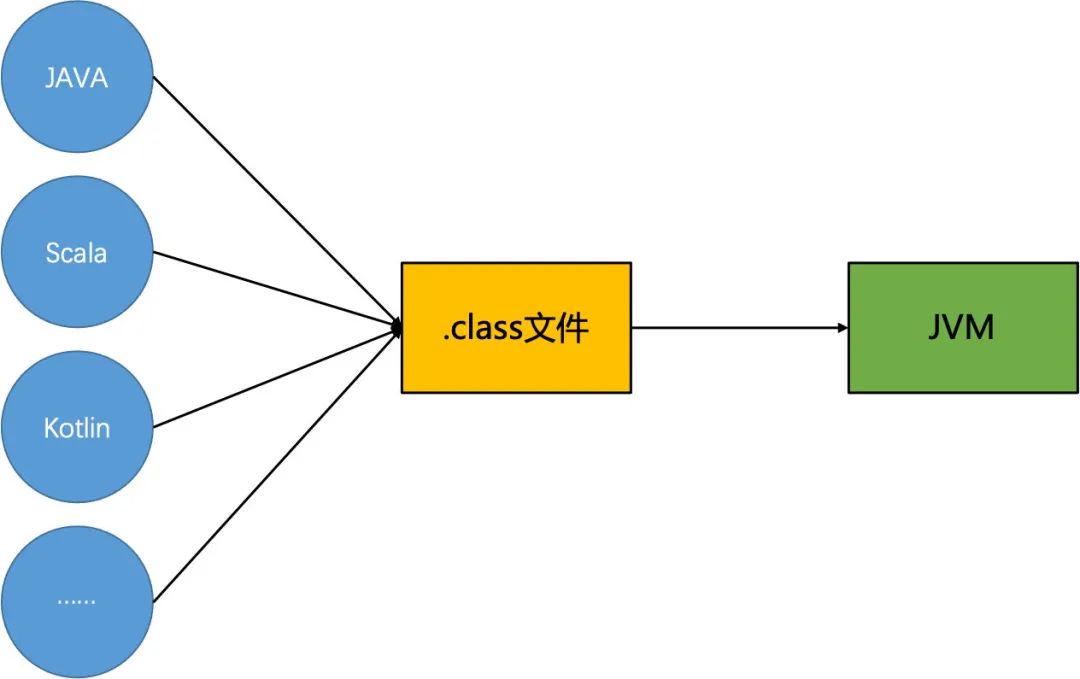
聪明的你很快就能发现,既然虚拟机运行需要的其实是class文件,因此它对于最前面用的是什么语言其实并不关心,只要支持生成JVM能够识别的字节码就行了。
难道说……
没错,恭喜你发现了JVM虚拟机**”跨语言“的特性**。
很多语言依赖了这种特性,将自己本身的源代码,编译生成class文件,并基于JVM虚拟机运行。比较常用的有Scala和Kotlin等,它们甚至可以跟Java语言相互调用,因为最终都是要编译成class文件到虚拟机中运行嘛,所以即使在源代码阶段是不同的语言,经过编译器之后,大家都变成了一样的字节码。
当然,要是再极端一点,由于class文件本质上也是一个二进制的文件,因此只要你足够强,能够徒手写出自己需要的二进制文件,你也就不再需要编译器了(狗头保命)。
很多读者就要说了:”我们是来学技术的,不是来学仙术的“。

先别笑,直接改字节码并不是什么天上飞的仙术,而是实打实的技术。像我们熟悉的lombok,就能够根据我们编写的注解生成字节码,实现字节码的修改增强(但lombok也是利用了编译器的一些特性,是在编译阶段触发操作的)。
类似的还有诸如ASM等一些字节码增强技术,也是通过直接操作字节码来实现的。
通过字节码增强技术可以实现热部署等操作,让你修改代码之后无需重启服务就能生效;也可以实现日志注入等功能,在不需要改变客户端调用方式情况下完成对指定方法增加缓存或日志的功能。
但对于大部分的普通开发者来说,编译器还是必不可少的。
编译阶段
当调用javac命令,触发java代码的编译过程,将.java文件编译成了.class二进制文件。
那么,在编译器中,源代码到底是怎么一步步变化的呢。
注意:javac是javac编译器的自带的命令,但市面上可用的并不只有javac这一种编译器,有一些其他的厂商也根据java的标准开发了自己的编译器。例如Eclipse的ecj(the Eclipse Compiler for Java)等。
只是大部分人用的都是JDK自带的javac的编译器,因此下文的讨论都是基于javac编译器展开的。
可以这样理解,编译的过程就是”编“和”译“。
编:将java源代码的结构组织成合适的格式,包括编译过程中的抽象语法树和符号表等,并在最终将源码编码成为class文件。
译:对源代码中的语义进行解析,并准确地翻译成另一种形式(字节码)。这一步既要确保原格式正确(Java源代码中的语法正确),又要确保翻译后的字节码跟源代码表达的意思一致。
也就是说,编译的过程要保证 输入的格式符合Java语言规范,输出的格式符合Java虚拟机规范。
这个过程说起来复杂,但是读者可以回忆一下自己经历过的代码编译失败的场景,每一次编译失败都是编译器在默默工作的结果,不同的错误可能是在编译过程的不同阶段被发现并抛出的。
接下来,我们循序渐进地告诉大家编译的具体步骤,以及编译过程的各个阶段抛出的不同编译异常。
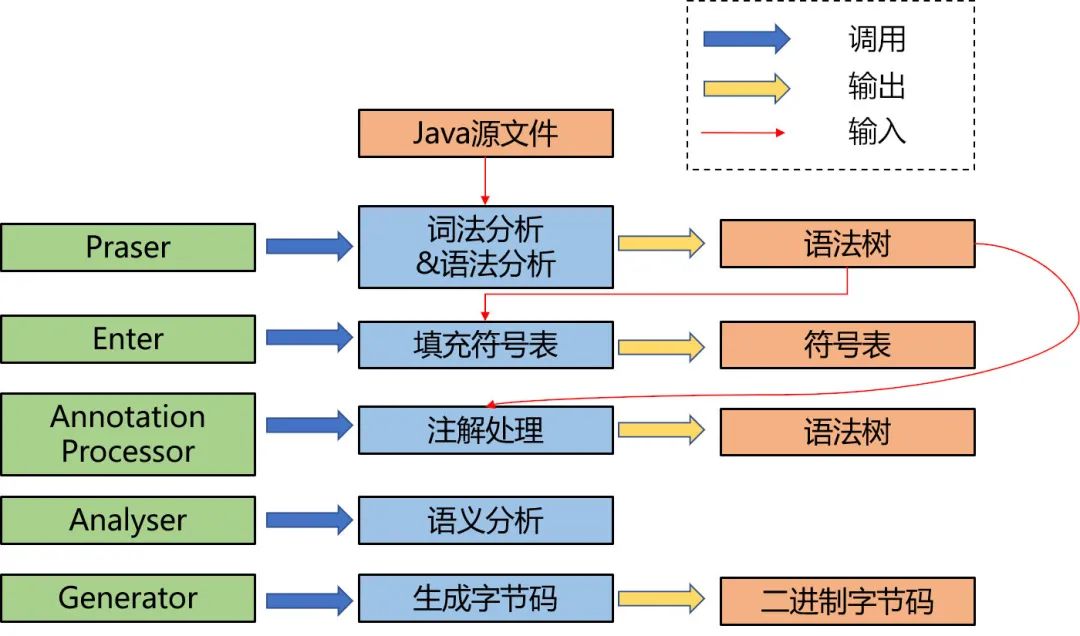
东西看起来很多哈,总结起来大概可以分为下面几个步骤:
1. 词法分析&语法分析
词法分析是最开始的一步,主要的作用就是把源代码的字符流转换成Token集合,Token是指代码中具有独立语义且不可再分的标记。
这里要注意,一个Token指的并不是单个的字符,而是具有实义的词。而且,编译器还会识别不同的词法类型,为它分配对应的Token类型,比如,int就会被识别为Token.INT ,运算符也会被分配为对应的Token类型,例如+就是Token.PLUS:
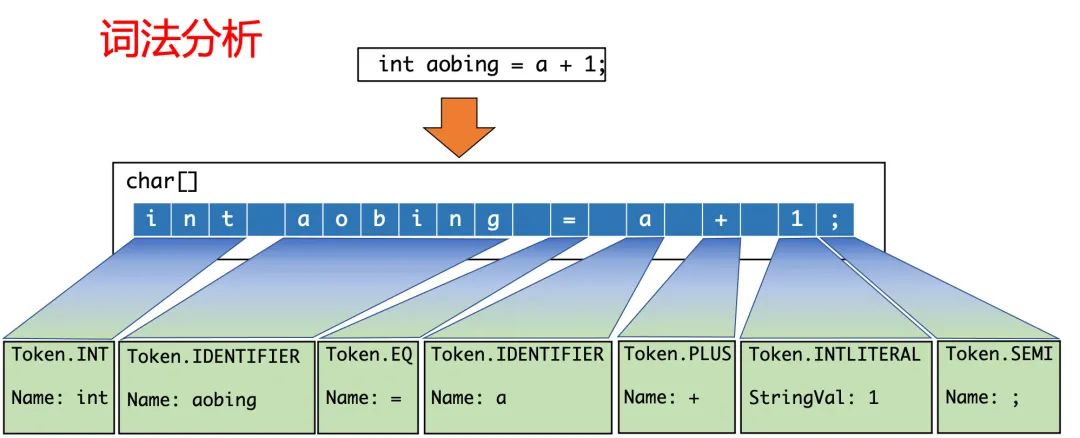
当代码被解析为一系列的Token集合之后,下一步是进行语法分析。
语法分析是根据解析后的Token集合,解析出抽象语法树(Abstract Syntax Tree, AST),AST中包含了java代码中的层级结构。
小知识:在NLP等领域的研究中,语法树也是用来分析语法规则及原理的重要手段,在这里不过多阐述。

根据这个结构,可以层级地展示代码中所有的变量、方法甚至是注释等各种信息。
构建AST的过程会判断Token的类型与其在树中的位置是否匹配,这一步我们很好理解哈,你用关键字作为变量名称的时候编译会不通过,就是在这一步被逮到的。
例如,你用这样一段代码去编译:
public class Hello {
public static void main(String[] args) {
String enum = "world";
System.out.println("Hello world");
}
}
会报如下的错误:
error: as of release 5, 'enum' is a keyword, and may not be used as an identifier
因为enum是关键字,构建语法树的时候发现堂堂一个关键字居然出现在了标识符的位置,这可使不得啊!
因此AST树构建失败,编译报错。
词法分析&语法分析是对源代码中文本的抽象,将.java源代码中的文本结构按照编译器特定的规则拆分、解析,为后续的编译工作铺平了道路,后面的操作都离不开这个AST。
2. 填充符号表
符号表就是由符号地址(位置)和符号信息构成的”表格“,它存储的是标识所对应的类型、作用域等。
这里说它是”表格“可能会对读者产生一定的误解,实际上它不是像我们想象的那种二维的表格,而是更接近hashTable那样的键值对结构,符号表可以由数组、树状结构或者栈等各种结构来实现。
这个符号表在后续的很多步骤都能发挥作用,例如:
static char x;
int foo() {
int x;
{
float x;
}
}
这段代码有三个同名变量,聪明的读者肯定能够分辨它们各自的作用域,但是笨笨的计算机没办法那么快分清它们的区别。
为了在解析符号和类型的时候分清它们的作用域而不产生使用冲突,就需要通过符号表来记录关系。
填充符号表的过程可以描述为:
-
将每个AST的顶层节点都放到待处理的列表中,并逐个处理; -
将所有的类符号(类的声明,名称)都输出到外层的作用域的符号表中; -
如果发现有package-info.java文件(描述整个包的信息和包内的常量),将其顶层节点放到待处理的列表中; -
明确泛型类型的真实类型; -
如果类中没有任何构造器,则添加默认的无参构造器; -
将类中符号输入到类自身的符号表中。
这一步有点抽象了,大家也不用太纠结于细节,能够明白大概的流程和目的就行了,只需要理解,这一步就是为了生成记录了类中符号的类型、属性等信息的符号表,方便后续流程中的应用。
强调一下5,学过java基础的都知道,如果一个类没有定义构造器,则会默认一个默认构建无参构造器,添加默认构造器的操作也是在填充符号表时完成的。
为什么呢?
很简单,因为类的构造方法也是需要放到符号表里记录的,而且不能为空,既然你没有指定,那我就给你放一个默认的空参构造器,然后记录到符号表咯。
相关的源码就放着这里了,大家有兴趣可以深挖一下。http://hg.openjdk.java.net/jdk8u/jdk8u/langtools/file/2baeb96fa198/src/share/classes/com/sun/tools/javac/comp/Enter.java
3. 注解处理
自从JDK 5以来,Java提供了对注解的支持,现在程序中使用注解已经是非常常规的操作。
然而要注意的是,并不是所有的注解都是在编译期起作用的,我们平时用反射处理的注解主要是指运行时注解,运行时注解在编译期不受影响,在编译之后的class文件中还是会保留,最终要在class文件到JVM运行的过程中才生效。
而编译期注解是指以@Retention(RetentionPolicy.SOURCE)定义的,在编译期就处理了的注解,这一类注解不会保留到class文件中。
听起来很懵,但其实编译过程中这一步注解处理其实大家在无意中已经接触过很多次了,比如大家常用的lombok,就是在这一步起作用的。
lombok采用的就是编译期注解处理的方法,因此当我们编译好用了lombok注解的.java文件后,打开生成的class文件就可以看到lombok相关的注解已经消失,而相应的getter、setter方法则已经被注入到class文件中。
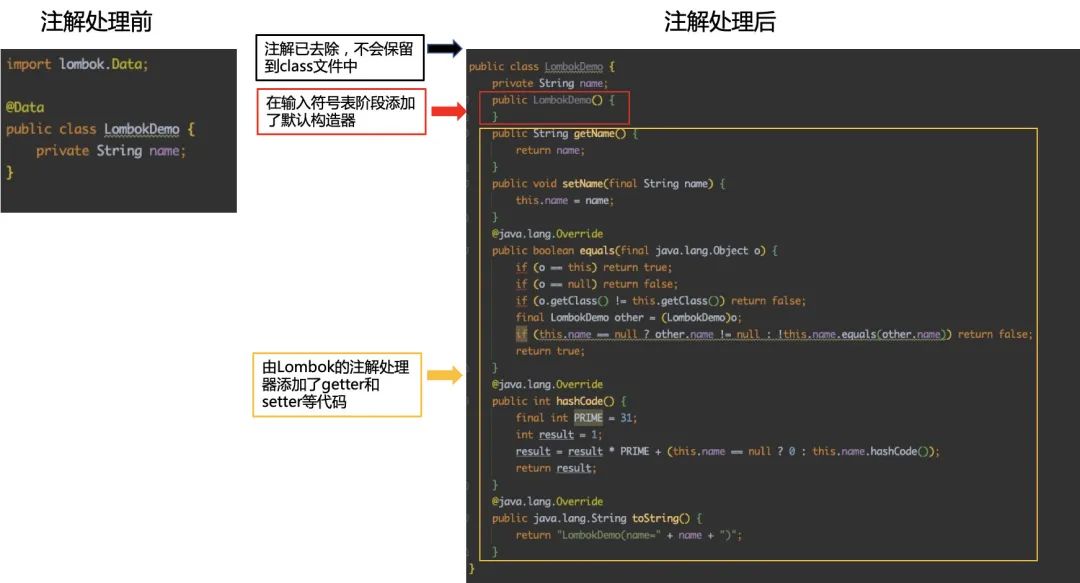
上图中右图展示的并不是class文件,而是与添加lombok注解等效的源代码,左右两侧的代码生成的字节码是一致的。
在这一步,lombok的注解处理器生效,并对我们前面所说的抽象语法树AST进行增强处理。
首先找到@Data注解所在类对应的语法树(AST),然后修改该语法树(AST),增加getter和setter方法定义的相应树节点,实现我们所需的功能。
这一步也是为数不多的,编译器留给程序员自己编写代码来影响源代码编译过程的机会。
注解处理完成后,可能又会产生新的符号,因此如果执行了注解处理,需要再执行一次解析和填充符号表的操作(回到第2步)。
4. 语义分析
语义分析听起来跟第一步词法分析&语法分析看起来很像,但其实是有很大区别。
我们类比成语文来解释:
“吃你饭今天了吗?”。
词法分析的步骤相当于把这一句话拆成了你、吃、今天、饭、了、吗、?,这几个词语。每个词都没问题。
可是到了语义分析阶段,我们再根据规则检查这句话的语义,发现这句话其实是不通顺的。
回到编译过程中来解释,语义分析的功能就是从结构和规则上对源代码进行检查,包括声明检查和类型检查等等。
这里我们用周志明老师书中的一个例子来说明:
假设有如下3个变量定义的语句:
int a = 1;
boolean b = false;
char c= 2;
int d =a + c;
int e = b + c;
char f = a + c;
这一段代码能够通过第一步的词法分析和语法分析,并构成正确的AST,但是在语义分析中会报错。因为编译器发现变量e和f的运算都是不符合规范的,参与运算的两个值的类型不匹配该运算符的逻辑。
语义分析更进一步检查上下文中变量的规范性,例如变量是否已经声明,变量的数据类型与其参与的运算是否匹配等等。
如果要对语义分析做细分的话,可以分为以下几个小阶段:
4.1 标注检查
这就是刚才说的,检查变量是否事先声明以及运算类型是否匹配的步骤,而且这一步的处理会影响到AST的结构:
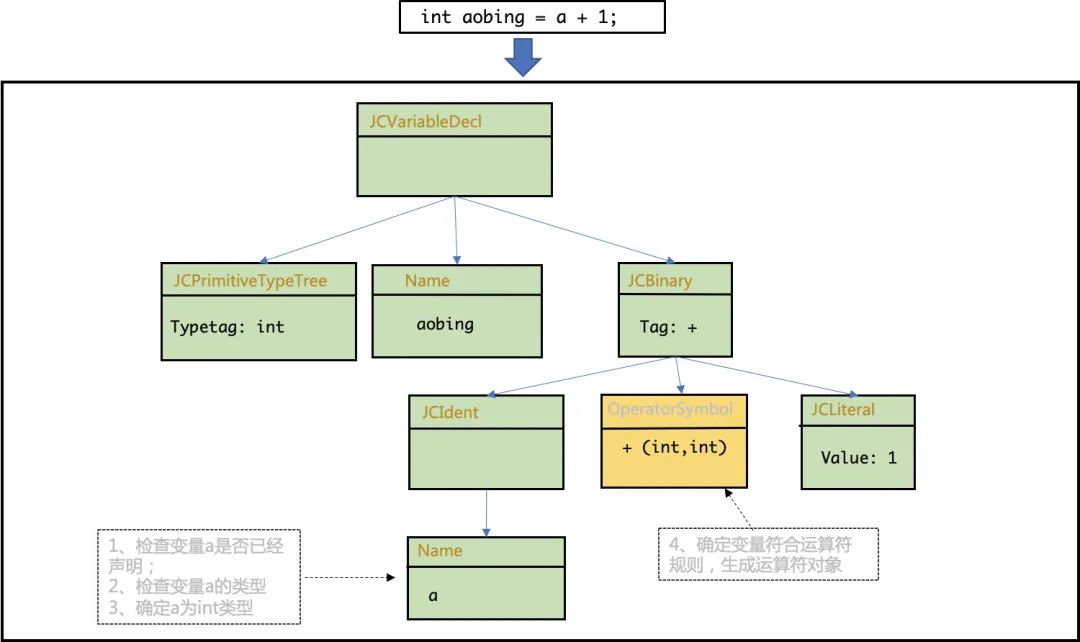
注意图中所示,我**们首先需要检查变量a有没有声明(声明检查),并检查a的类型(类型检查),这两个检查都需要用上我们前文已经填充完成的符号表,从符号表中查询变量的作用域和类型,**完成语义分析的检查。
然后判断运算符和另一个运算值的类型,检查左右运算值的类型是否匹配,能否参与运算。
看到了吗,在这里AST和符号表就共同发挥作用啦。
此外,标注检查步骤还有两个很重要的操作:
-
泛型方法类型的推导:
在这一步就需要明确泛型方法传递的真实类型是什么了;
-
常量折叠(Constant Folding):
这是一个很有意思的操作,它会进行一些简单的常量计算,例如:
int a = 1 + 2;在这一步就会被优化为a = 3,优化之后在AST中还是能够看到int、a、1、+、2、;这几个标记,但是这个表达式的值已经被计算出来了,并在AST上进行了标注。也就是说,现在的AST既保留了表达式的结构,也记录了表达式的结果。当后续到虚拟机中去执行字节码的时候,由于编译期常量折叠的优化,
int a = 3和int a = 1 + 2的运行效率其实是一样的,因为这一个常量的运算在编译期已经做完,不会再额外消耗运行期的处理时间。一般的代码优化都是要到生成字节码之后,等到运行期在虚拟机的解释器中再进行的。而常量折叠是javac编译器对源代码做的极少量的优化措施之一,也是为数不多的编译期对代码进行优化的操作。
4.2 数据流分析
数据流分析是在标注检查之后的进一步检验,主要检验是局部变量在使用前是否确定性赋值、声明有返回值的方法是否有确定性的返回值等。
值得注意的是,final变量不可重复赋值的性质也是在这一步检查,如果一个final变量被重复赋值,编译器会发现并报错的。也正是因为这个特性,用final关键字局部变量只会在编译期去校验,不会对在运行期产生任何作用 。
有如下的例子:
// 方法1
public void aobingTest(final int nezha){
final int a = 0;
}
// 方法2
public void aobingTest(int nezha){
int a = 0;
}
这两个方法产生的字节码是一模一样的,没有任何的差别。因此所有的final不可重复赋值的限制,都在编译期得到了检验,如果声明为final的局部变量被重复赋值,在编译期就会报错,如果没有发现有final重复赋值的错误,才会成功生成字节码。
因此对于运行期来说,局部变量是否声明为final,不会有任何校验的步骤(因为局部变量不管有没有用final限制,生成的字节码都是一样的,字节码中不会保留局部变量是否声明为final的信息)。
5. 解语法糖
简单地来说,语法糖就是方便程序员编写的便捷写法,这种语法不会对最终的结果产生实际影响,但能够减少程序编写者的工作量。
例如,java中的自动拆箱装箱功能、foreach循环功能等,都是为了程序员能够更写出更简洁流程的代码而封装的语法糖。
但是到了程序运行阶段,这样的语法糖对计算机来说是不可识别的。因此需要在编译阶段先解语法糖,将语法还原为它本来”笨拙“的样子。
例如,将包装类型拆成普通类型,将增强for循环替换为普通的for循环。
6. 生成Class文件
终于到了生成最终需要的class文件的一步了,前面所构建的语法树、符号表等信息,在这一步被转换成字节码指令写到class文件中,除此之外,还有两个非常重要的方法被添加到语法树中,他们分别是和方法。
注意,这两个长得像init的方法指的并不是类中的构造函数。
-
方法是一个类的构造器,它的作用是初试化所有的静态变量并执行用
static {}包裹的代码块,而且该方法的收集是有顺序的:将这些与类相关的初始化代码按顺序收集在一起生成了函数,在类加载的时候按顺序运行,所以方法相当于是把静态的代码打包在一起,等待后续统一执行。
-
父类静态变量初始化
-
父类静态语句块
-
子类静态变量初始化
-
子类静态语句块
-
方法其实是一个实例构造器,它的作用是初始化类中的成员变量,例如成员变量的赋值操作,以及被
{}符号包裹的代码块,这些方法都会被收敛到方法中成为一个跟对象初始化相关的方法。该方法的收集也是有顺序的:
-
父类代码块 -
父类构造函数 -
子类变量初始化 -
子类代码块 -
子类构造函数 -
父类变量初始化
通俗来说,这两个方法就是将源代码中的代码块和变量初始化的步骤按照静态与非静态分为了两类,并按一定顺序打包好,等待合适的时机执行。
对方法来说,这个合适的执行时机就是在类被加载的时候;
而对方法来说,执行的时机就是在该类new一个对象的时候。
由于类加载过程优先于对象实例化过程,所以方法一定比方法先执行。因此它们完整的执行顺序就是:
-
父类静态变量初始化 -
父类静态语句块 -
子类静态变量初始化 -
子类静态语句块 -
父类变量初始化 -
父类语句块 -
父类构造函数 -
子类变量初始化 -
子类语句块 -
子类构造函数
发现了吗,这就是常见的面试题:”java代码的加载顺序“的标准答案。
这个问题的本质其实在于:Java代码能够保持加载顺序的原因就是在生成class文件时,将按顺序拼接好的和方法添加到了class文件中,在后续的运行过程中再按顺序执行。
以后面试遇到这个问题知道怎么答了吗。
除了生成构造器之外,生成class文件时还会优化某些代码逻辑的实现方式,比如,将字符串的+运算操作,替换为StringBuffer或者StringBuilder的append()方法。
到此为止,java源代码到class文件的编译过程进入了尾声。
由于篇幅原因,今天暂时讲到Java代码编译为class文件的过程,后续我们再继续钻研class文件中的细节以及字节码最终在JVM中运行的流程。
一些思考
对了,还有一个问题可能是大家理解上的误区。
很多人会认为class文件 = 字节码,这是不对的,class文件并不等于字节码。我们从class文件的结构中可以窥见端倪,class文件中记录了如下的一些信息:
-
结构信息:class文件格式版本号; -
元数据:主要对应的是Java源代码中”声明“和”常量“对应的信息,包括类的声明信息、类中属性域与方法的声明信息、常量池等; -
方法信息:主要对应Java源代码中”语句“和”表达式“对应的信息,包括 字节码、异常处理器表、操作数栈和局部变量区的大小等;
这下就很清晰了,字节码是Class文件的一个子集,只是class文件中众多组成部分的其中之一。
乖,以后别再以为Class文件就是字节码了。




